Data Mining
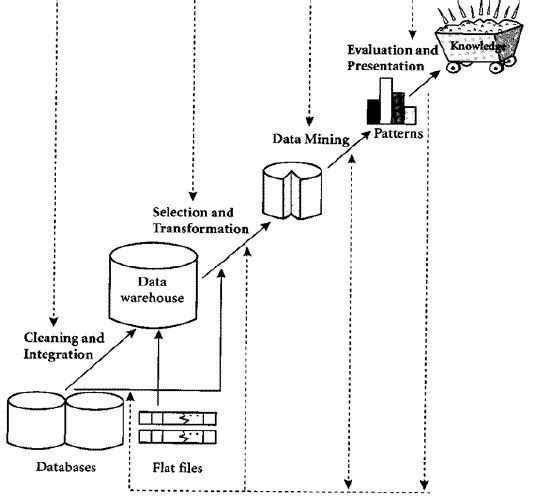
Data Mining adalah sebuah aktifitas dan bukanlah sebuah algoritma atau program. Dalam pelaksanaan aktifitas Data Mining maka seringkali digunakan berbagai teknik ataupun algoritma yang berasala dari berbagai disiplin ilmu misalnya statistik, artificial intelligence ataupun machine learning.
Data mining adalah proses menerapkan metode ini untuk data dengan maksud untuk mengungkap pola-pola tersembunyi. Dengan arti lain Data mining adalah proses untuk penggalian pola-pola dari data. Data mining menjadi alat yang semakin penting untuk mengubah data tersebut menjadi informasi. Hal inisering digunakan dalam berbagai praktek profil, seperti pemasaran, pengawasan, deteksi penipuan dan penemuan ilmiah. Telah digunakan selama bertahun-tahun oleh bisnis, ilmuwan dan pemerintah untuk menyaring volume data seperti catatan perjalanan penumpang penerbangan, data sensus dan supermarketscanner data untuk menghasilkan laporan riset pasar.
Proses Data Mining
Dikarenakan Data Mining adalah suatu rangkaian proses, Data Mining dapat dibagi menjadi beberapa tahap:
- Pembersihan data (untuk membuang data yang tidak konsisten dan noise).
- Integrasi data (penggabungan data dari beberapa sumber).
- Transformasi data (data diubah menjadi bentuk yang sesuai untuk di-mining).
- Aplikasi teknik Data Mining.
- Evaluasi pola yang ditemukan (untuk menemukan yang menarik/bernilai).
- Presentasi pengetahuan (dengan teknik visualisasi)
- Tahapan diatas tersebut bersifat interaktif di mana pemakai terlibat langsung atau dengan perantaraan knowledge base.
Teknik Data Mining
Berikut beberapa jenis teknik Data Mining yang paling populer dikenal dan digunakan:
Association Rule Mining
Association rule mining adalah teknik mining untuk menemukan aturan assosiatif antara suatu kombinasi item. Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, yaitu support dan confidence. Support yaitu persentase kombinasi item tersebut dalam database dan confidence yaitu kuatnya hubungan antar item dalam aturan assosiatif. Algoritma yang paling populer dikenal sebagai Apriori dengan paradigma generate and test, yaitu pembuatan kandidat kombinasi item yang mungkin berdasar aturan tertentu lalu diuji apakah kombinasi item tersebut memenuhi syarat support minimum. Kombinasi item yang memenuhi syarat tersebut disebut frequent item set,yang nantinya dipakai untuk membuat aturan-aturan yang memenuhi syarat confidence minimum. Algoritma baru yang lebih efisien bernama FP-Tree.
Classification
Classification adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui. Model itu sendiri bisa berupa aturan "jika-maka", berupa decision tree, formula matematis atau neural network. Decision tree adalah salah satu metode classification yang paling populer karena mudah untuk diinterpretasi oleh manusia. Disini setiap percabangan menyatakan kondisi yang harus dipenuhi dan tiap ujung pohon menyatakan kelas data. Algoritma decision tree yang paling terkenal adalah C4.5, tetapi akhir-akhir ini telah dikembangkan algoritma yang mampu menangani data skala besar yang tidak dapat ditampung di main memory seperti RainForest. Metode-metode classification yang lain adalah Bayesian, neural network, genetic algorithm, fuzzy, case-based reasoning, dan k-nearest neighbor. Proses classification biasanya dibagi menjadi dua fase, learning dan test. Pada fase learning, sebagian data yang telah diketahui kelas datanya diumpankan untuk membentuk model perkiraan. Kemudian pada fase test, model yang sudah terbentuk di uji dengan sebagian data lainnya untuk mengetahui akurasi dari model tersebut. Bila akurasinya mencukupi model ini dapat dipakai untuk prediksi kelas data yang belum diketahui.
Clustering
Berbeda dengan association rule mining dan classification dimana kelas data telah ditentukan sebelumnya. Clustering melakukan pengelompokan data tanpa berdasarkan kelas data tertentu. Bahkan clustering dapat dipakai untuk memberikan label pada kelas data yang belum diketahui itu. Karena itu clustering sering digolongkan sebagai metode unsupervised learning. Prinsip dari clustering adalah memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan kesamaan antar kelas/cluster. Clustering dapat dilakukan pada data yan memiliki beberapa atribut yang dipetakan sebagai ruang multi-dimensi. Banyak algoritma clustering memerlukan fungsi jarak untuk mengukur kemiripan antar data, diperlukan juga metode untuk normalisasi bermacam atribut yang dimiliki data. Beberapa kategori algoritma clustering yang banyak dikenal adalah metode partisi dimana pemakai harus menentukan jumlah k partisi yang diinginkan lalu setiap data dites untuk dimasukkan pada salah satu partisi, metode lain yang telah lama dikenal adalah metode hierarki yang terbagi dua lagi, yaitu, bottom-up yang menggabungkan cluster kecil menjadi cluster lebih besar dan top-down yang memecah cluster besar menjadi cluster yang lebih kecil.
Kelemahan 3 teknik/metode ini adalah bila bila salah satu penggabungan/pemecahan dilakukan pada tempat yang salah, tidak dapat didapatkan cluster yang optimal. Pendekatan yang banyak diambil adalah menggabungkan metode hierarki dengan metode clustering lainnya.
Implementasi (Penerapan)
Dalam bidang apasaja data mining dapat diterapkan? Berikut beberapa contoh bidang penerapan data mining:
1. Analisa pasar dan manajemen
Solusi yang dapat diselesaikan dengan data mining, diantaranya:
- Menembak target pasar.
- Melihat pola beli pemakai dari waktu ke waktu,
- Cross-market analysis.
- Profil Customer.
- Identifikasi kebutuhan customer.
- Menilai loyalitas Customer.
- Informasi Summary.
2. Analisa Perusahaan dan Manajemen resiko
Solusi yang dapat diselesaikan dengan data mining, diantaranya:
- Perencanaan keuangan dan Evaluasi aset.
- Perencanaan sumber daya (Resource Planning).
- Persaingan (Competition).
3. Telekomunikasi
Sebuah perusahaan telekomunikasi menerapkan data mining untuk melihat dari jutaan transaksi yangmasuk, transaksi mana sajakah yang masih harus ditangani secara manual.
4. Keuangan
Financial Crimes Enforcement Network di Amerika Serikat baru-baru ini menggunakan data mining untuk menambang trilyunan dari berbagai subyek seperti properti, rekening bank dan transaksi keuangan lainnya untuk mendeteksi transaksi-transaksi keuangan yang mencurigakan (seperti money laundry).
5. Asuransi
Australian Health Insurance Commision menggunakan data mining untuk mengidentifikasi layanan kesehatan yang sebenarnya tidak perlu tetapi tetap dilakukan oleh peserta asuransi.
6. Olahraga
IBM Advanced Scout menggunakan data mining untuk menganalisis statistik permainan NBA (jumlah shots blocked, assists dan fouls) dalam rangka mencapai keunggulan bersaing (competitive advantage) untuk tim-tim NBA.
7. Astronomi
Jet Propulsion Laboratory (JPL) di Pasadena, California dan Palomar Observatory berhasil menemukan 22 quasar dengan bantuan data mining. Hal ini merupakan salah satu kesuksesan penerapan data mining di bidang astronomi dan ilmu ruang angkasa.
8. Internet Web surf-aid
IBM Surf-Aid menggunakan algoritma data mining untuk mendata akses halaman Web, khususnya yang berkaitan dengan pemasaran guna melihat prilaku dan minat customer serta melihat keefektifan pemasaran melalui Web.
Referensi:
kompasiana.com
Machine Learning

Apa itu Machine Learning ?
Machine Learning adalah metode yang digunakan untuk membuat program yang bisa belajar dari data. Berbeda dengan program komputer biasa yang statis, program machine learning adalah program yang dirancang untuk mampu belajar sendiri.
Cara belajar program machine learning mengikuti cara belajar manusia, yakni belajar dari contoh-contoh. Machine learning akan mempelajari pola dari contoh-contoh yang dianalisa, untuk menentukan jawaban dari pertanyaan-pertanyaan berikutnya.
Memang tidak semua masalah bisa dipecahkan dengan program machine learning. Namun, seringkali algoritma yang sifatnya kompleks, ternyata bisa dipecahkan dengan sangat simpel oleh machine learning. Beberapa contoh program machine learning yang telah digunakan dalam kehidupan sehari-hari:
- Pendeteksi Spam
- Pendeteksi Wajah
- Rekomendasi Produk
- Asisten Virtual
- Diagnosa Medis
- Pendeteksi Penipuan Kartu Kredit
- Pengenal Digit
- Perdagangan Saham
- Segmentasi Pelanggan
- Mobil yang bisa Mengendarai Sendiri
Kita bisa mengklasifikasikan machine learning berdasarkan tipe-tipe:
Supervised Learning :
- Regression adalah data yang ada diberikan real value, numerical atau floating point, agar dapat mencoba mendeteksi harga saham di kemudian hari. Contoh: time series data dari harga saham berdasarkan waktu.
- Classification (Discrete/ Category) adalah data yang ada diberikan label atau kategori, agar dapat diambil keputusan berdasarkan label/ kategori tersebut.
Unsupervised Learning (Clustering)
Data tidak diberikan label, tapi secara otomatis dibagi berdasarkan kemiripan dan struktur lain dari data tersebut. Misalnya, ketika kita mengorganisasikan foto. Kita harus melakukan tagging secara manual
Reinforcement Learning
Data digunakan untuk melakukan pemberian label If dan Else yang digunakan untuk mengambil keputusan berdasarkan tree pengambil keputusan.
Machine learning adalah seperti membuat program yang bisa menebak kotak hitam yang memiliki rumus fungsi yang belum diketahui. Kotak hitam itu diberikan sebuah input dan akan menghasilkan sebuah output tertentu. Dari data-data input dan output yang diperoleh, maka program akan menebak rumus fungsi yang paling mendekati keakuratan.

Adapun alur kerja Machine Learning mencakup:
- Mengumpukan dataset
- Eksplorasi data
- Pemilihan model (regresi linear, regresi logistik, neural network, dll)
- Memberikan latihan terhadap model yang dipilih
- Evaluasi Model
- Prediksi
Akurasi awal dari program machine learning biasanya sangat buruk. Sebab pada awalnya program ini ‘tidak tahu apa-apa’. Namun, seiring berjalannya waktu, semakin sering kita melatih program, semakin banyak contoh-contoh yang dipelajari oleh program, maka program ini akan semakin ‘cerdas’ dan akurat.
Misalnya saja saat kita bermain game Role Playing Game (RPG) yang menggunakan Artificial Intelligence. Pertama kali kita bermain dengan RPG tersebut, maka dengan mudah kita akan bisa memenangkan permainan. Namun, setelah beberapa kali permainan, engine/ algoritma game itu akan belajar dari pola-pola sebelumnya, sehingga akan semakin sulit dikalahkan.
*) Disarikan dari materi presentasi Welly Tambunan ( Solution Architect Bank Danamon) pada acara Machine Learning Street Fighter, di Makers Institute, 11 Januari 2018.
Referensi :medium.com
Data Mining vs Machine Learning

Perbedaan antara Data mining dan Machine Learning
Data Mining mengacu pada penggalian pengetahuan dari sejumlah besar data. Data Mining adalah proses untuk menemukan berbagai jenis pola yang diwariskan dalam data dan mana yang akurat, baru dan bermanfaat. Data Mining adalah bagian dari analisis bisnis, mirip dengan penelitian eksperimental. Asal-usul penggalian data adalah database, statistik. Machine Learning melibatkan algoritme yang meningkat secara otomatis melalui pengalaman berdasarkan data. Machine Learning adalah cara untuk menemukan algoritma baru dari pengalaman. Machine Learning melibatkan studi tentang algoritma yang dapat mengekstraksi informasi secara otomatis. Machine Learning menggunakan teknik penambangan data dan algoritma pembelajaran lainnya untuk membangun model apa yang terjadi di balik beberapa data sehingga dapat memprediksi hasil di masa depan.
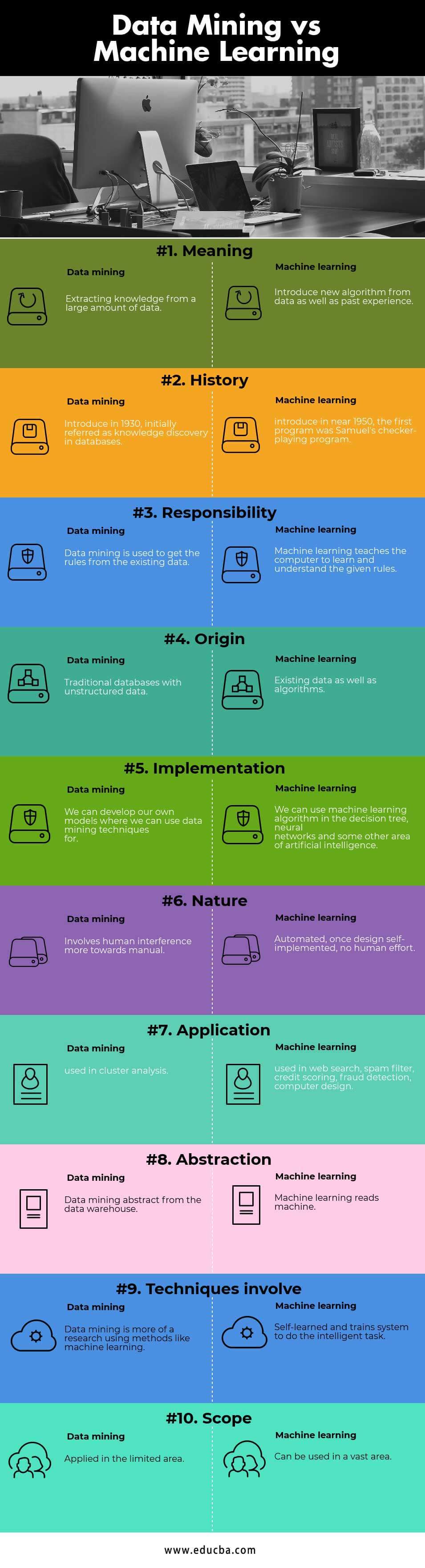
Kunci perbedaan diantara Data Mining & Machine Learning
- Untuk menerapkan teknik data mining, digunakan dua komponen yang pertama adalah basis data dan yang kedua adalah Machine Learning. Basis data menawarkan teknik manajemen data sementara Machine Learning menawarkan teknik analisis data. Tetapi untuk menerapkan teknik Machine Learning itu menggunakan algoritma.
- Penambangan data menggunakan lebih banyak data untuk mengekstraksi informasi yang berguna dan bahwa data tertentu akan membantu untuk memprediksi beberapa hasil di masa depan misalnya dalam perusahaan penjualan yang menggunakan data tahun lalu untuk memprediksi penjualan ini tetapi Machine Learning tidak akan banyak bergantung pada data yang menggunakan algoritma, misalnya , OLA, teknik Machine Learning UBER untuk menghitung ETA untuk wahana.
- Kapasitas belajar mandiri tidak ada dalam penggalian data, ini mengikuti aturan dan yang telah ditentukan. Ini akan memberikan solusi untuk masalah tertentu tetapi algoritma Machine Learning didefinisikan sendiri dan dapat mengubah aturan mereka sesuai skenario, itu akan menemukan solusi untuk masalah tertentu dan menyelesaikannya dengan caranya sendiri.
- Perbedaan utama dan terpenting antara Data Mining dan Machine Learning adalah, tanpa keterlibatan Data Mining manusia tidak dapat bekerja tetapi dalam Machine Learning upaya manusia hanya melibatkan waktu ketika algoritma didefinisikan setelah itu akan menyimpulkan semuanya dengan cara sendiri setelah diterapkan selamanya digunakan tetapi ini tidak terjadi dengan data mining.
- Hasil yang dihasilkan oleh Machine Learning akan lebih akurat dibandingkan dengan data mining karena Machine Learning adalah proses otomatis.
- Penambangan data menggunakan database atau server data warehouse, mesin Data Mining dan teknik evaluasi pola untuk mengekstraksi informasi yang berguna sedangkan Machine Learning menggunakan jaringan saraf, model prediktif dan algoritma otomatis untuk membuat keputusan.
Kesimpulan dari Data Mining vs Machine Learning
Dalam sebagian besar kasus sekarang Data Mining digunakan untuk memprediksi hasil dari data historis atau menemukan solusi baru dari data yang ada. Sebagian besar organisasi menggunakan teknik ini untuk mendorong hasil bisnis. Di mana teknik Machine Learning tumbuh dengan cara yang jauh lebih cepat karena mengatasi masalah dengan apa yang dimiliki teknik Data Mining. Karena proses pembelajaran Mesin lebih akurat dan lebih sedikit kesalahan jika dibandingkan dengan Data Mining dan itu jauh lebih mampu untuk mengambil keputusan sendiri dan menyelesaikan masalah. Tetapi untuk mendorong bisnis tetap, kita perlu memiliki proses Data Mining karena akan menentukan masalah bisnis tertentu dan untuk menyelesaikan masalah tersebut kita dapat menggunakan teknik Machine Learning. Dalam satu kata kita dapat mengatakan bahwa untuk menggerakkan bisnis, baik teknik Data Mining dan Machine Learning harus bekerja bahu-membahu, satu teknik akan menentukan masalahnya dan lainnya akan memberi Anda solusi dengan cara yang jauh lebih akurat.
Referensi :
Comments
Post a Comment